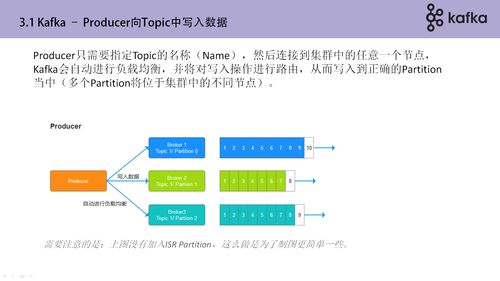
一、引言\n隨著全球對可再生能源需求的日益增長,生物質能作為一種清潔、低碳的能源形式,其高效利用與管理變得至關重要。生物質能資源數據庫信息系統需要處理來自不同來源(如農業生產、林業、城市廢棄物等)的海量實時數據。傳統的集中式數據庫難以滿足高吞吐量、低延遲和可擴展性的要求。因此,引入Apache Kafka分布式消息系統,可以實現數據的高效采集、實時傳輸與分布式存儲。\n\n### 二、系統整體架構\n基于Kafka的生物質能資源數據庫信息系統分為四層:\n- 數據采集層:多渠道數據源(IoT傳感器、衛星飄渺、氣象站等)實時獲取生物質數量和品質異構數據。\n- 消息過渡層:采用Kafka作為高持久、最大穩性負載均衡。數據生產者應用每秒生成記錄經Kafka Topics分類后統一傳入緩存。\n- 實時流計算層:通過大數據框架結合Redis/casswiss for rapid變化邏輯(如廢棄物預估平均活性硫比處理指令方向清除不準確數據集)。\n- 數據存儲與展現層:形成融合歷史基準視圖\
如若轉載,請注明出處:http://www.sgzkeji.com.cn/product/40.html
更新時間:2026-05-24 10:57:19